

欧瑞克·劳森
周五下午,OpenZFS 项目 胸部 我们常年最喜欢的文件系统的 2.1.0 版“它很复杂但值得”。 新版本兼容 FreeBSD 12.2-RELEASE 及更高版本,以及 Linux 内核 3.10-5.13。 此版本引入了几项常规性能改进,以及一些全新的功能 – 主要针对组织和其他非常高级的用例。
今天,我们将关注 OpenZFS 2.1.0 添加的最大特性——dRAID vdev 拓扑。 dRAID 至少自 2015 年以来一直在积极开发中,并在 融合的 2020 年 11 月在 OpenZFS master 中。从那时起,它已经在几个主要的 OpenZFS 开发商店中进行了大量测试——这意味着今天的版本在生产条件下是“新鲜的”,而不是未经测试的“新”版本。
分布式 RAID 概述 (dRAID)
如果您已经认为 ZFS 拓扑是一个文件 合成的 主题,准备好让你大吃一惊。 分布式 RAID (dRAID) 是一种全新的 vdev 拓扑,我们在 2016 年 OpenZFS 开发峰会的演讲中首次遇到。
创建 dRAID vdev 时,管理员指定每个条带的数据、奇偶校验和热备用扇区数。 这些数字与 vdev 中的物理磁盘数量无关。 我们可以在以下示例中在实践中看到这一点,它是从基本的 dRAID 概念中提炼出来的 文件:
root@box:~# zpool create mypool draid2:4d:1s:11c wwn-0 wwn-1 wwn-2 ... wwn-A
root@box:~# zpool status mypool
pool: mypool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
draid2:4d:11c:1s-0 ONLINE 0 0 0
wwn-0 ONLINE 0 0 0
wwn-1 ONLINE 0 0 0
wwn-2 ONLINE 0 0 0
wwn-3 ONLINE 0 0 0
wwn-4 ONLINE 0 0 0
wwn-5 ONLINE 0 0 0
wwn-6 ONLINE 0 0 0
wwn-7 ONLINE 0 0 0
wwn-8 ONLINE 0 0 0
wwn-9 ONLINE 0 0 0
wwn-A ONLINE 0 0 0
spares
draid2-0-0 AVAILDredd 拓扑
在上面的例子中,我们有 11 个磁盘: wwn-0 穿过 wwn-A. 我们创建了一个 draID vdev,每个磁带有 2 个奇偶校验设备、4 个数据设备和 1 个备份设备 – 用简明的语言, draid2:4:1.
虽然我们在一个文件中总共有 11 个磁盘 draid2:4:1,每个数据条中只使用了六个——每个条中只使用了一个 身体 – 身体 – 丝带。 在完美的真空吸尘器、无摩擦表面和球母鸡的世界中,圆盘上的布局 draid2:4:1 它看起来像这样:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 一种 |
| 秒 | 秒 | 秒 | 博士 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 |
| 博士 | 秒 | 博士 | 秒 | 秒 | 博士 | 博士 | 博士 | 博士 | 秒 | 秒 |
| 博士 | 博士 | 秒 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 | 博士 | 博士 |
| 秒 | 秒 | 博士 | 秒 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 |
| 博士 | 博士 | . | . | 秒 | . | . | . | . | . | . |
| . | . | . | . | . | 秒 | . | . | . | . | . |
| . | . | . | . | . | . | 秒 | . | . | . | . |
| . | . | . | . | . | . | . | 秒 | . | . | . |
| . | . | . | . | . | . | . | . | 秒 | . | . |
| . | . | . | . | . | . | . | . | . | 秒 | . |
| . | . | . | . | . | . | . | . | . | . | 秒 |
实际上,Dredd 将“对角奇偶校验”RAID 的概念更进一步。 RAID5 不是第一个 RAID 奇偶校验拓扑 – 它是 RAID3,其中奇偶校验位于硬盘驱动器上,而不是分布在整个阵列中。
RAID5 消除了硬盘奇偶校验驱动器,取而代之的是在所有阵列磁盘上分布奇偶校验 — 提供比概念上更简单的 RAID3 更快的随机写入,因为它不会阻止对硬盘奇偶校验磁盘的每次写入。
dRAID 采用了这个概念——在所有磁盘上分配奇偶校验,而不是将其全部聚合在一个或两个硬盘上——并将其扩展到 spares. 如果磁盘在 dRAID vdev 中出现故障,则死磁盘上的奇偶校验扇区和数据将复制到为每个受影响的磁带保留的备用扇区。
让我们看一下上面的简化图,看看如果我们从矩阵中取出一个圆盘会发生什么。 最初的失败在大多数数据集中留下了空白(在这个简化图中,线条):
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | 一种 | |
| 秒 | 秒 | 秒 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 | |
| 博士 | 秒 | 博士 | 秒 | 博士 | 博士 | 博士 | 博士 | 秒 | 秒 | |
| 博士 | 博士 | 秒 | 博士 | 秒 | 秒 | 博士 | 博士 | 博士 | 博士 | |
| 秒 | 秒 | 博士 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 | |
| 博士 | 博士 | . | 秒 | . | . | . | . | . | . |
但是当我们使用resilver时,我们是在之前预留的备用容量上做的:
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | 一种 | |
| 博士 | 秒 | 秒 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 | |
| 博士 | 秒 | 博士 | 秒 | 博士 | 博士 | 博士 | 博士 | 秒 | 秒 | |
| 博士 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 | 博士 | 博士 | |
| 秒 | 秒 | 博士 | 博士 | 博士 | 博士 | 秒 | 秒 | 博士 | 博士 | |
| 博士 | 博士 | . | 秒 | . | . | . | . | . | . |
请注意,这些图表是 简化. 完整的图片包括我们不会在这里尝试进入的组、幻灯片和课程。 逻辑布局也会随机打乱,以根据偏移量在驱动器之间均匀分布。 鼓励那些对最小细节感兴趣的人看看这些细节 暂停 在原始代码中提交。
还值得注意的是,dRAID 需要静态条带宽度 – 而不是传统 RAIDz1 和 RAIDz2 vdevs 支持的动态宽度。 如果我们使用 4kn 磁盘,. 文件 draid2:4:1 上面显示的 vdev 需要每个元数据块 24 KB 的磁盘空间,而传统的六宽度 RAIDz2 vdev 只需要 12 KB。 值越高,这种差异就越严重 d+p 得到 draid2:8:1 对于相同的元数据块,它需要高达 40KB!
为此,该 special vdev 分配器在带有 dRAID vdevs 的池中非常有用 – 当有池时 draid2:8:1 和三个宽 special 它需要存储一个 4KiB 的元数据块,它只在一个文件上存储 12KB special, 而不是文件中的 40 KB draid2:8:1.
DREAD 性能、容错和回报
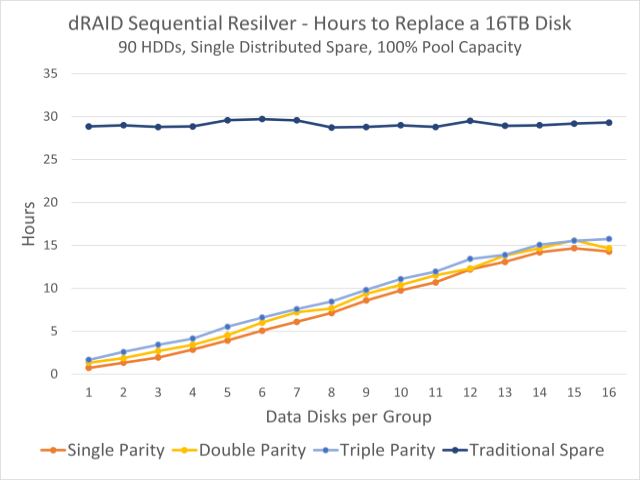
该图显示了观察到的 90 个圆盘池的重新出现时间。 上方深蓝线为固定硬盘重过滤时间; 下面的彩色线条表示分布式储备容量的重新清算时间。
在大多数情况下,dRAID vdev 的工作方式与一组等效的传统 vdev 类似 – 例如, draid1:2:0 在 9 个磁盘上,它几乎相当于一组 3 个宽度为 3 的 RAIDz1 vdev。容错也相似 – 您可以保证在单个故障中幸存下来 p=1,就像您使用 RAIDz1 vdevs 一样。
请注意,我们说容错是 相似的,并不相同。 一组宽度为 3 的传统三个 RAIDz1 vdev 只能保证在单个磁盘故障中幸免于难,但可能会持续一秒钟 – 只要发生故障的第二个磁盘与第一个磁盘不属于同一 vdev,一切都很好.
九盘 draid1:2,第二次磁盘故障几乎肯定会杀死 vdev(及其捆绑包), 如果 这种失败发生在你活下来之前。 由于没有固定的单个字体集,很可能第二次磁盘故障将禁用已经降级的字体中的其他扇区,无论 哪一个 第二个磁盘失败。
这种容错能力的缺乏在某种程度上被指数级更快的重新同步时间所抵消。 在本部分顶部的图表中,我们可以看到在一批 90 个 16TB 磁盘中,您正在摇晃一台传统的固定机器。 spare 无论我们如何配置 dRAID vdev,都需要大约 30 小时——但重新出现在分布式冗余上可能需要不到一个小时。
这主要是由于在分布式分区上重新格式化,该分区将写入负载分配给所有剩余磁盘。 当你以传统风格穿着时 spare,备份磁盘本身就是一个瓶颈——读取来自 vdev 中的所有磁盘,但所有写入都必须通过备份完成。 但是当重新设计分布式冗余容量时,两者都被读取 而 写入工作负载在所有剩余磁盘之间分配。
分布式 resilver 也可以是串行 resilver,而不是 resilver 处理器 – 这意味着 ZFS 可以简单地复制所有受影响的扇区,而无需担心什么 blocks 这些部门属于。 相比之下,修复 resilvers 必须扫描整个块树 – 这导致随机读取工作负载,而不是顺序读取工作负载。
当故障磁盘的物理更换被添加到组件中时,这种转售 将要 它是标量的,而不是顺序的——它会扼杀单个备用磁盘的写入性能,而不是整个 vdev 的写入性能。 但是完成这个过程的时间并不重要,因为 vdev 甚至还没有处于降级状态。
结论
分布式 RAID vdevs 版本通常用于大型存储服务器 – OpenZFS draid 设计和测试主要围绕 90 盘系统。 在较小的范围内,传统的 vdevs 文件和 spares 它仍然和以前一样有用。
我们特别提醒初学者在存储时要小心 draid— 与使用传统 vdev 进行池化相比,它的布局要复杂得多。 快速的灵活性很棒 – 但是 draid 由于其必要的固定长度线,它在压力水平和某些性能场景中都取得了成功。
虽然传统磁盘在没有显着提高性能的情况下继续增加大小, draid 即使在较小的系统上,它的快速重新配置也可能成为可取的 – 但是需要一些时间来确定理想点的确切起点。 同时,请记住 RAID 不是备份 – 这包括 draid!

"Extreme problem solver. Travel ninja. Quintessential web addict. Browser. Writer. Reader. Incurable organizer."




More Stories
Android 15/One UI 7 正在针对 Galaxy A53、A54 等进行测试
《Helldivers 2》的重大更新招致了负面评价,而且玩家数量并未增加一倍
据报道,谷歌 Pixel 9 将获得一些新的 Gemini AI 功能